Algumas operações de tecnologias podem ser paralelizadas utilizando mais CPUs para processar determinadas tarefas, e no banco de dados não é diferente. A opção PARALLEL X, onde X é a quantidade de cores a ser utilizada permite dividir a consulta em pequenos pedaços fazendo com que cada processador execute parte da query.
No exemplo abaixo estou paralelizando a consulta entre 20 cpus com o comando PARALLEL 20 e suspendi a geração de REDO LOG com o NOLLOGGING. Essa operação é lenta, pois está comprimindo uma tabela de 500GB e movendo para outra tablespace, a TD_MOVELOB:
[code lang=”sql”]
ALTER TABLE GALOMG.TB_LOG COMPRESS FOR OLTP;
ALTER TABLE GALOMG.TB_LOG MOVE TABLESPACE TD_MOVELOB NOLOGGING PARALLEL 20;
[/code]
Para checar se a consulta está paralelizada, basta executar o select abaixo na LONGOPS que trará uma linha para cada processo dividido:
[code lang=”sql”]
SELECT inst_id,sid, serial#, opname, username,start_time,last_update_time,
round(time_remaining/60,2) "REMAIN MINS", round(elapsed_seconds/60,2) "ELAPSED MINS", round((time_remaining+elapsed_seconds)/60,2) "TOTAL MINS",
ROUND(SOFAR/TOTALWORK*100,2) "%_COMPLETE", message
FROM gv$session_longops
WHERE TOTALWORK != 0 AND sofar<>totalwork AND time_remaining > 0;
[/code]
Abaixo o resultado da query, onde msotra que cada pedaço da query possui um SID diferente, mesmo que a tabela seja a mesma: GALOMG.TB_LOG !
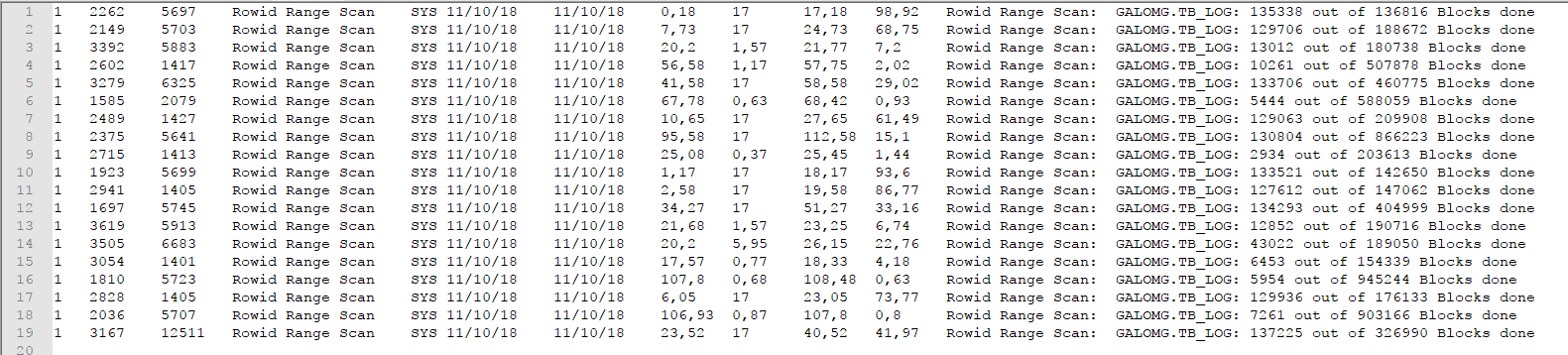
Basta executar a query várias vezes para consultar o tempo que cada pedaço da query está sendo executado.
